
Web Crawler Basics:
Have you ever wondered how it’s possible to get answers at your fingertips so quickly with search engines like Google and Bing? It’s easy to take this convenient access to information for granted.
Search engines are an excellent gateway for research and information gathering; however, their lesser-known sidekicks called web crawlers to play a critical role in accessing content online. They are also fundamental to your SEO strategy.
So you might be wondering what web crawlers are. Keep reading this web crawler explanation article to learn more!
Web crawlers are called many different names, including bots, robots, and spiders. These descriptive names summarize what crawlers do – they crawl the Internet to index pages for search engines.
Search engines do not automatically know which websites are out on the Internet. They need to have programs to crawl and index sites before delivering the correct pages for phrases and keywords or the words that people use to find a helpful page.
It is like shopping for groceries in a brand new store.
You need to walk down all of the aisles and search for products before you can choose what you need.
Similarly, web crawler programs are used by search engines to scour the Internet looking for pages before the page data is stored to be used in future searches.
Search engine crawlers need to have a starting place – a link – before seeing the following link and the subsequent pages.
How do web crawlers work?
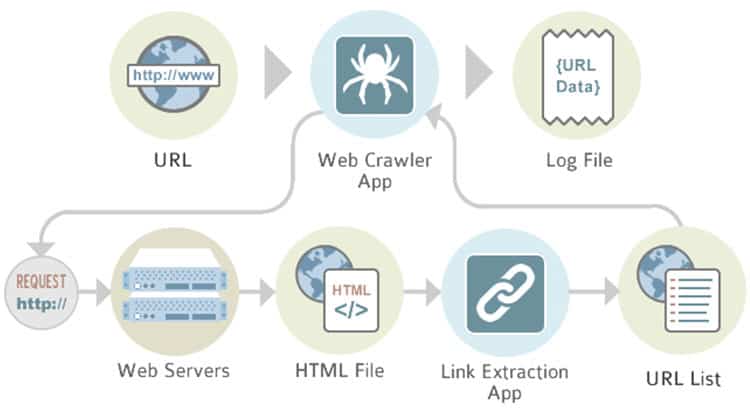
The search engines visit or crawl websites by passing between the various links associated with different websites. However, if your website is brand new without links connecting your website’s pages with others, you can request that the search engines crawl your site. Google, for instance, allows you to submit your website to their crawlers via a tool called Google Search Console.
Free Web Crawler Simulator

If you have ever wanted to see how a web crawler looks at your website, check our our free spider simulator tool. It’s designed to mimic how search engines like google and bing see your webpage.
Crawlers work as explorers in new lands.
Crawlers constantly search for and discover links on web pages and place them in their directories after understanding their contents. However, website crawlers only navigate through a website’s public pages. Private pages that cannot be crawled are classified as the “deep web.”
While web crawlers are on a page, they collect information about it, such as the meta tags and the copy. The crawlers then store these pages in their index so the search engine algorithms can sort them for their contained words to retrieve and rank for its users later on.
Web crawler examples
All major search engines have web crawlers, with the big ones having multiple crawlers with specific focuses.
For instance, Googlebot is Google’s main crawler, which does both desktop and mobile crawling. Google has several other bots, including AdsBot, Googlebot News, Googlebot Videos, and Googlebot Images.
There are several other web crawlers you might have encountered:
- Bingbot
- Baidu’s Baiduspider
- Yandex’s Yandex Bot
- DuckDuckGo’s DuckDuckBot
Bing has a web crawler as well called Bingbot, along with more specific bots, such as BingPreview and MSNBot-Media. MSNBot used to be its main crawler. It has taken a backseat when it comes to standard crawling and now just performs minor crawl duties.
Why web crawlers are so important for SEO
SEO involves improving your website for improved rankings. This requires that web crawlers be able to access and read your pages. The first way that the search engine accesses your pages is through crawling. Regular re-crawling of a page’s contents helps them maintain an up-to-date footprint of any changes or updates that have been added.
Keep reading this article to learn more about the relationship between SEO and web crawlers.
Crawl budget management
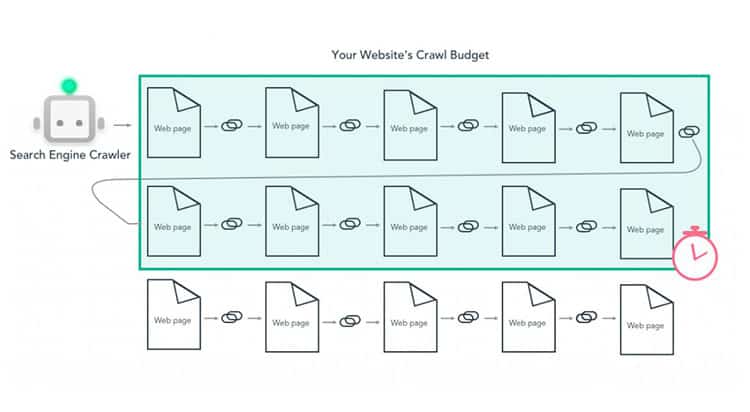 Continuous web crawling provides your recently published pages the opportunity to be displayed within the search engine results pages (SERPs). But you are not provided with unlimited crawling from the major search engines, including Google.
Continuous web crawling provides your recently published pages the opportunity to be displayed within the search engine results pages (SERPs). But you are not provided with unlimited crawling from the major search engines, including Google.
Google has its own crawl budget in place that provides its bots with guidance on:
- How frequently to crawl
- Which pages should be scanned
- Acceptable server pressure
Instituting a crawl budget is a good idea. Otherwise, the activity of visitors and crawlers can overload your website.
If you would like your website to continue to operate smoothly, your web crawling can be adjusted through your crawl demand and crawl rate.
Fetching on websites is monitored by the crawl rate limit so that a surge of errors does not occur and the load speed does not suffer. If you are experiencing issues with Googlebot, you can change your website crawl rate within the Google Search Console.
The crawl demand refers to the level of interest that users and Google have for your website. So, if you do not yet have a large following, then Googlebot will not crawl your website as frequently as more popular sites
Web Crawler Roadblocks
There are a couple of ways to block web crawlers from being able to access your pages on purpose. Not every single page on your website needs to rank in the SERPs. Crawler roadblocks can help to protect irrelevant, redundant, or sensitive pages from being displayed for keywords.
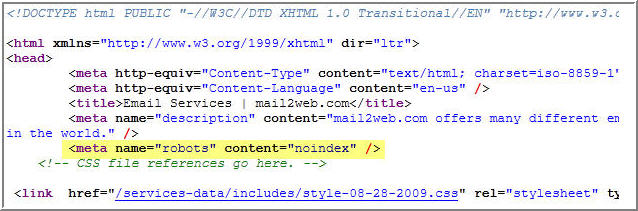
Noindex Meta Tag
The noindex meta tag is the first meta tag. This prevents search engines from being able to index and rank a specific page. Usually, it is a good idea to apply noindex to your internal search results, thank you pages, and admin pages.
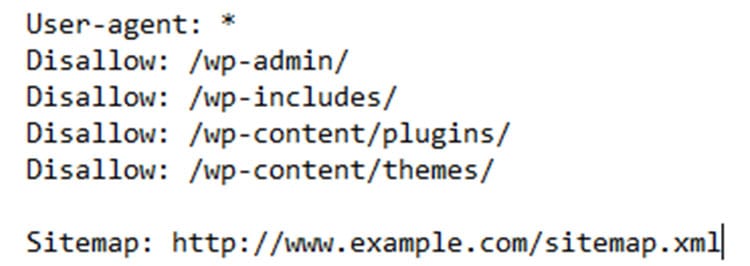
Robots.txt
The robots.txt file is another crawler roadblock. It isn’t a definitive directive since crawlers can opt out from conforming to your robots.txt files. However, it helps to control your crawl budget.
Now that we have covered the basics of crawling, we should have answered your question of “what are web crawlers?” The search engine crawlers are amazing powerhouses for locating and recording pages on websites.
It is a foundational building block of your overall SEO strategy. Then the gaps can be filled in by an SEO company and provide a robust campaign to your business to increase rankings in the SERPs, traffic, and revenue.
As a leading SEO Services provider and local web design company, we work for our clients to help increase their customer base by using search engine optimization. Since 2009, we have helped improve the exposure and revenue of both national and local companies by boosting the visibility of a website in the major search engines such as Yahoo, Bing, and Google.
We achieve this by having a dedicated web design assigned to you and getting a series of strategic alterations implemented to your web design to increase its online reach and topical relevance.
Are you ready to work with an award-winning digital marketing firm and take the next step?
Get in touch with our Enleaf team today to start enjoying better marketing results.